Rilasciato OpenZFS 2.1 – Parliamo del nuovissimo dRAID vdevs

Oric Lawson
Venerdì pomeriggio, il progetto OpenZFS il petto Versione 2.1.0 del nostro file system preferito da sempre “È complicato ma ne vale la pena”. La nuova versione è compatibile con FreeBSD 12.2-RELEASE e versioni successive e kernel Linux 3.10-5.13. Questa versione introduce diversi miglioramenti generali delle prestazioni, nonché alcune funzionalità completamente nuove, principalmente rivolte alle organizzazioni e ad altri casi d’uso molto avanzati.
Oggi ci concentreremo sulla più grande funzionalità aggiunta da OpenZFS 2.1.0: la topologia dRAID vdev. dRAID è in sviluppo attivo almeno dal 2015 e ha raggiunto lo stato beta quando integrato Nel master OpenZFS a novembre 2020. Da allora, è stato ampiamente testato in diversi importanti negozi di sviluppo OpenZFS, il che significa che la versione odierna è “fresca” in produzione, non “nuova” come non testata.
Panoramica RAID distribuito (dRAID)
Se pensavi già che la topologia ZFS fosse un file composito Soggetto, preparati a farti impazzire. Il RAID distribuito (dRAID) è una topologia vdev completamente nuova che abbiamo incontrato per la prima volta in una presentazione all’OpenZFS Dev Summit 2016.
Quando si crea un dRAID vdev, l’amministratore specifica il numero di dati, parità e settori hotspare per ogni striscia. Questi numeri sono indipendenti dal numero di dischi fisici in vdev. Possiamo vederlo in pratica nel seguente esempio, che è tratto dai concetti di base di dRAID documentazione:
root@box:~# zpool create mypool draid2:4d:1s:11c wwn-0 wwn-1 wwn-2 ... wwn-A
root@box:~# zpool status mypool
pool: mypool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
draid2:4d:11c:1s-0 ONLINE 0 0 0
wwn-0 ONLINE 0 0 0
wwn-1 ONLINE 0 0 0
wwn-2 ONLINE 0 0 0
wwn-3 ONLINE 0 0 0
wwn-4 ONLINE 0 0 0
wwn-5 ONLINE 0 0 0
wwn-6 ONLINE 0 0 0
wwn-7 ONLINE 0 0 0
wwn-8 ONLINE 0 0 0
wwn-9 ONLINE 0 0 0
wwn-A ONLINE 0 0 0
spares
draid2-0-0 AVAILTopologia Dredd
Nell’esempio sopra, abbiamo undici dischi: wwn-0 Attraverso wwn-A. Abbiamo creato un vdev draID con 2 dispositivi di parità, 4 dispositivi di dati e 1 dispositivo di backup per nastro – in un linguaggio condensato, draid2:4:1.
Anche se abbiamo undici dischi in totale in un file draid2:4:1, ne vengono utilizzati solo sei in ogni barra dati — e uno in ogni barra fisico – fisico – nastro. In un mondo di aspirapolveri perfetti, superfici prive di attrito e galline, il layout sul disco draid2:4:1 Apparirà così:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | un |
| S | S | S | Dr | Dr | Dr | Dr | S | S | Dr | Dr |
| Dr | S | Dr | S | S | Dr | Dr | Dr | Dr | S | S |
| Dr | Dr | S | Dr | Dr | S | S | Dr | Dr | Dr | Dr |
| S | S | Dr | S | Dr | Dr | Dr | S | S | Dr | Dr |
| Dr | Dr | . | . | S | . | . | . | . | . | . |
| . | . | . | . | . | S | . | . | . | . | . |
| . | . | . | . | . | . | S | . | . | . | . |
| . | . | . | . | . | . | . | S | . | . | . |
| . | . | . | . | . | . | . | . | S | . | . |
| . | . | . | . | . | . | . | . | . | S | . |
| . | . | . | . | . | . | . | . | . | . | S |
In effetti, Dredd porta il concetto di RAID a “parità diagonale” un passo avanti. RAID5 non era la prima topologia di parità RAID: era RAID3, in cui la parità si trovava su un disco rigido, anziché distribuita nell’array.
RAID5 ha eliminato l’unità disco rigido e ha compensato la distribuzione della parità su tutti i dischi dell’array, fornendo scritture casuali molto più veloci rispetto a RAID3 concettualmente più semplice, perché non ha impedito ogni scrittura su un disco rigido con parità.
dRAID prende questo concetto – distribuire la parità su tutti i dischi, piuttosto che aggregarlo tutto su uno o due dischi rigidi – e lo estende a spares. Se il disco si guasta in dRAID vdev, i settori di parità ei dati che risiedono sul disco morto vengono copiati nei settori di riserva riservati per ciascun nastro interessato.
Prendiamo il grafico semplificato sopra e vediamo cosa succede se togliamo un disco dalla matrice. L’errore iniziale lascia delle lacune nella maggior parte dei set di dati (in questo diagramma semplificato, linee):
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | un | |
| S | S | S | Dr | Dr | Dr | S | S | Dr | Dr | |
| Dr | S | Dr | S | Dr | Dr | Dr | Dr | S | S | |
| Dr | Dr | S | Dr | S | S | Dr | Dr | Dr | Dr | |
| S | S | Dr | Dr | Dr | Dr | S | S | Dr | Dr | |
| Dr | Dr | . | S | . | . | . | . | . | . |
Ma quando usiamo resilver, lo facciamo sulla capacità di riserva precedentemente riservata:
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | un | |
| Dr | S | S | Dr | Dr | Dr | S | S | Dr | Dr | |
| Dr | S | Dr | S | Dr | Dr | Dr | Dr | S | S | |
| Dr | Dr | Dr | Dr | S | S | Dr | Dr | Dr | Dr | |
| S | S | Dr | Dr | Dr | Dr | S | S | Dr | Dr | |
| Dr | Dr | . | S | . | . | . | . | . | . |
Si prega di notare che questi grafici sono semplificato. Il quadro completo include gruppi, segmenti e righe che non cercheremo di approfondire qui. Il layout logico viene anche mescolato casualmente per distribuire le cose in modo uniforme tra le unità in base all’offset. Coloro che sono interessati ai più piccoli dettagli sono incoraggiati a dare un’occhiata a questi dettagli Sospensione Nel codice originale commit.
Vale anche la pena notare che dRAID richiede larghezze di stripe statiche, non le larghezze dinamiche supportate dai tradizionali RAIDz1 e RAIDz2 vdevs. Se stiamo usando dischi 4kn, il file draid2:4:1 Un vdev come quello mostrato sopra richiederà 24 KB su disco per blocco di metadati, mentre un vdev RAIDz2 convenzionale a sei larghezze richiede solo 12 KB. Questa discrepanza peggiora all’aumentare dei valori d+p Ottenere draid2:8:1 Richiederebbe ben 40 KB per lo stesso blocco di metadati!
Per questo motivo il special L’allocatore vdev è molto utile sui pool con vdev dRAID – quando c’è un pool con esso draid2:8:1 e tre larghe special Ha bisogno di memorizzare un blocco di metadati da 4KiB, lo fa in soli 12KB su special, invece di 40 KB in un file draid2:8:1.
Prestazioni DREAD, tolleranza agli errori e rimborso
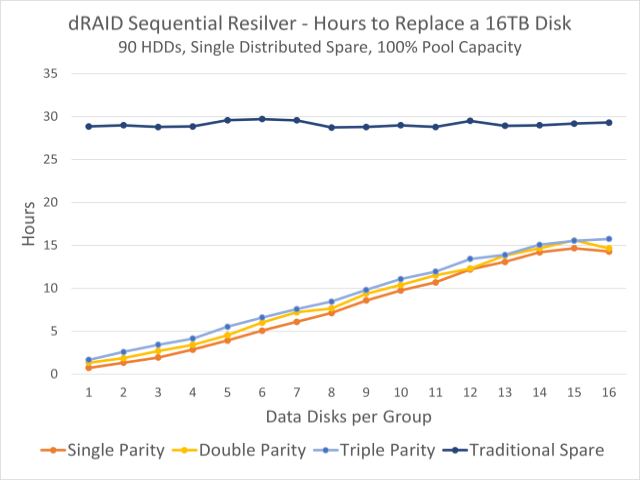
Questo grafico mostra i tempi di riemergere osservati per un pool di 90 dischi. La linea blu scuro in alto è il tempo di re-filtro su un hard disk fisso; Le linee colorate sottostanti indicano i tempi di riliquidazione della capacità di riserva distribuita.
Per la maggior parte, dRAID vdev funzionerà in modo simile a un set equivalente di vdev tradizionali, ad esempio draid1:2:0 Su nove dischi funzionerà in modo quasi equivalente a un set di tre vdev RAIDz1 di larghezza 3. Anche la tolleranza agli errori è simile: sei sicuro di sopravvivere a un singolo errore con p=1, proprio come con RAIDz1 vdevs.
Nota che abbiamo detto che la tolleranza agli errori è simile, non erano identici. Un set tradizionale di tre vdev RAIDz1 di larghezza 3 è garantito per sopravvivere solo a un guasto di un singolo disco, ma probabilmente durerà per un secondo, purché il secondo disco che si guasta non faccia parte dello stesso vdev del primo, tutto va bene .
in nove dischi draid1:2, un secondo errore del disco quasi certamente ucciderebbe vdev (e il bundle con esso), Se Questo fallimento si verifica prima che tu sopravviva. Poiché non ci sono set fissi di caratteri individuali, è molto probabile che un secondo guasto del disco disabiliti settori aggiuntivi nei caratteri già danneggiati, indipendentemente da Quale Il secondo disco non è riuscito.
Questa mancanza di tolleranza ai guasti è in qualche modo compensata da tempi di resilver esponenzialmente più veloci. Nel grafico nella parte superiore di questa sezione, possiamo vedere che in un batch di novanta dischi da 16 TB, viene riconfigurato su una macchina fissa convenzionale. spare Ci vogliono circa trenta ore, indipendentemente da come configuriamo dRAID vdev, ma la ricomparsa sulla ridondanza distribuita può richiedere meno di un’ora.
Ciò è in gran parte dovuto alla riformattazione su una partizione distribuita che divide il carico di scrittura tra tutti i dischi rimanenti. Quando lo indossi in stile tradizionale spare, il disco di backup stesso è un collo di bottiglia: le letture provengono da tutti i dischi in vdev, ma tutte le scritture devono essere completate con il backup. Ma quando la capacità ridondante distribuita viene ridisegnata, vengono lette entrambe E il I carichi di lavoro di scrittura sono divisi tra tutti i dischi rimanenti.
Un resilver distribuito può anche essere un resilver sequenziale, piuttosto che un resilver di ripristino, il che significa che ZFS può semplicemente copiare tutti i settori interessati, senza preoccuparsi di blocks Questi settori appartengono a. Al contrario, il refactoring di guarigione deve esaminare l’intero albero dei blocchi, il che si traduce in un carico di lavoro di lettura casuale, piuttosto che un carico di lavoro di lettura sequenziale.
Quando la sostituzione fisica del disco guasto viene aggiunta all’assieme, questa rivendita volere È uno scavenger, non sequenziale e ridurrà le prestazioni di scrittura per un singolo disco di riserva, piuttosto che quello dell’intero vdev. Ma il tempo per completare questo processo è molto meno importante, perché vdev non è nemmeno in uno stato di degrado.
Conclusioni
Le versioni Vdev RAID distribuite sono spesso destinate a server di archiviazione di grandi dimensioni – OpenZFS draid La progettazione e il collaudo ruotavano in gran parte intorno a sistemi a 90 dischi. Su scala ridotta, file vdevs tradizionali e spares Rimane utile come prima.
In particolare, avvertiamo i principianti in deposito di fare attenzione con loro draid—È un layout significativamente più complesso rispetto al pooling con vdev tradizionali. La presa rapida è ottima, ma draid Raggiunge il successo sia nei livelli di stress che in determinati scenari di prestazioni grazie alle sue linee di lunghezza necessariamente fissa.
Mentre i dischi tradizionali continuano ad aumentare di dimensioni senza aumentare significativamente le prestazioni, draid La sua rapida riconfigurazione può diventare desiderabile anche nei sistemi più piccoli, ma ci vorrà del tempo per sapere esattamente da dove cominciare con il punto ideale. Nel frattempo, ricorda che RAID non è un backup – questo include draid!

“Comunicatore. Ninja web hardcore. Amante estremo dei social media. Analista. Drogato di alcol.”





